Redis cluster 中的 hashing
接 上篇文章 中的一致性 hash。最终理论上在集群发生变更时,可以尽可能少的降低缓存失效的情况, 但是毕竟还是有部分数据丢失了。还有实际在生产环境中部署时,还要考虑高可用。
所以后来就演变成了 twitter 开源的 twemproxy 架构,一个生产环境的 Redis 集群架构可能如下:
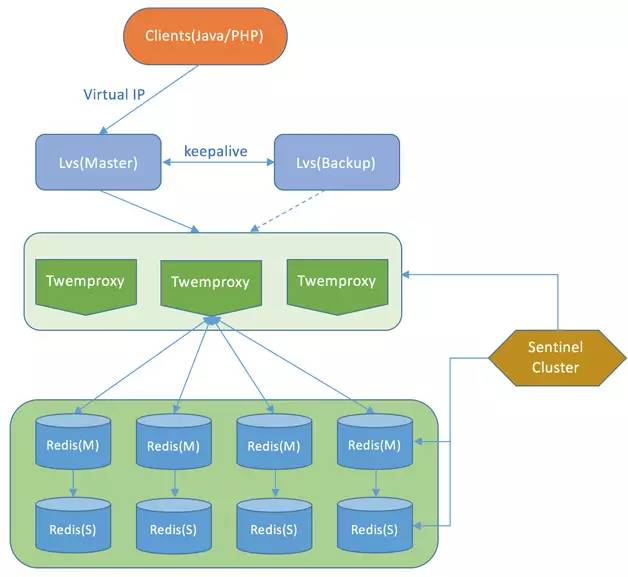
Figure 1: 图片来自网络,侵删
除了实现了高可用,业务端不用关心后端的 Sharding 逻辑,跟单独操作 Redis 一样,用起来很方便。 缺陷是结构比较复杂,运维成本很高,缩容扩容需要人工参与(除了修改 Master 和 Slave,还需要修改 Proxy), 最主要的是多了一层 Proxy 的转发,性能会有损耗。
好在 Redis 3.0 之后,官方提供了分布式集群方案。不同于 hash 一致性的方案,架构如下:
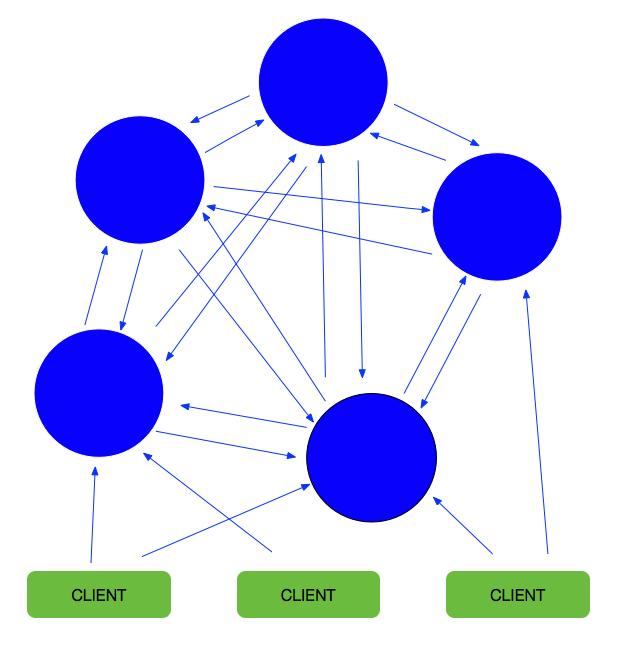
Figure 2: 图片来自网络,侵删
采用去中心化的思路,类似 P2P,每个 master 节点都保存整个集群的节点信息,master 节点能够自动发现其他的节点,检测节点是否正常, 当发现节点 failure 时,将 slave 自动提升为 master。
节点之间会定时做心跳检测,并同步各自的信息(节点ID、IP地址和端口、连接状态、节点负责的 hash slot 等),
slots 被设计为 16384 个( 2^14 ),也就是说理论上集群节点的个数为 16384,但实际上官方建议不超过 1000 个。
定义了公开的 hash 映射算法: HASH_SLOT = CRC16(key) mod 1638 。这样就省掉了前面架构中的 proxy 层。为什么是 16384 ?
添加节点和删除节点时集群会自动转移 slot 到新/旧节点中,期间对数据的读写会回复 MOVE 和 ASK 重定向,告诉客户端去哪里访问新的数据。
使用 Redis cluster 好处是上面所说的故障自动切换到 slave,添加和删除节点机会不会导致缓存失效(实际上会有一些), 架构比较简单、省去了 proxy 的性能损耗。缺点也是运维成本高,缩容扩容需要手工操作而且必要时需要手工调整 slot 分布。 还有个问题就是客户端实现相比单点的 Redis 会比较复杂,客户端需要缓存 slots 分布和 slots 的及时更新。
下面是 go 的 redis cluster client 实现方案中的部分逻辑:
连接集群
- 随便找到一个节点,执行
CLUSTER SLOTS- Redis 实例中 SLOT start -> end
- Redis 实例的 IP:PORT
- 根据返回值,建立 SLOT 和 Redis 实例相互的映射关系
- IP:PORT -> redis 实例
{address, connTimeout, readTimeout, writeTimeout, keepAlive, aliveTime} - 每个 SLOT -> redis 实例
- IP:PORT -> redis 实例
- 有节点需要 update 时,重新执行 1,2
写入数据
- 通过 key 计算 hash 值,找到 slot
- 通过 slot 找到 redis 实例
- 与实例建立 conn 然后写入数据
- 检查 redis 返回值
- 处理 cluster 的 MOVE 消息 -> 执行上面「连接集群」中的 update 更新集群信息
- 处理 cluster 的 ASK 消息 -> 转向另外一个节点请求
可以看到需要自己建立 slot 和 redis node 的映射关系,在节点发生变更时实时的重新 update 集群信息,并且要自己实现 hash 算法。 如果多种语言连接同一个库的时候,hash 策略不同时会导致 key 映射混乱(proxy 统一做 hash 就不会有这个问题)。