[译] 一致性 hash 指南
Table of Contents
原文为 A Guide to Consistent Hashing,这两天在看 Redis Cluster 相关资料提到了 consistent hash,看了一些资料,这篇文章写的不错,就翻译了一下。
hash 有时可被翻译成哈希,有时可被翻译成散列,文中保留英文的 hash。意译非旨意,理解思想就好。
近些年,随着云计算和大数据等概念的出现,分布式系统越来越被普及。
分布式缓存为许多高流量的动态网站和 Web 应用程序提供支持,通常由特定的分布式 hashing 组成。称之为一致性 Hash 算法。
什么是一致性 hash ?它背后的动机是什么,以及为什么要关心它?
在本文中,我将首先回顾一下 hash 的一般概念和它的目的,然后是分布式 hash 的介绍以及它存在的问题。这也是我们这篇文章的核心部分。

1. Hashing 是什么?
什么是「Hashing」?Merriam-Webster 定义了名词 hash 是『切碎的肉混合和土豆和褐色』,动词含义是『将(肉和土豆)切成小块』。 所以除了烹饪细节之外,hash 大体意味着『切割和混合』– 这也是技术术语的来源。
hash 函数是用来将数据映射的函数 - 通常是把任意大小的某种数据映射成另外一块数据,通常是整数,称之为 hash 码(hash code),或者简单的称为 hash。
例如,一些 hash 函数设计来专门用户映射字符串,输出为 0 .. 100 的数字,比如把 hello 映射为数字 57 ,
Hasta la vista, baby 映射为数字 33 。由于输出的内容范围大于输出的内容范围,因此任何给定的数字都可能对应许多不同的字符串,
这称之为 碰撞 。好的 hash 函数应该以某种方式更好的「切割和混合」输入使得输出的范围尽可能的均匀的扩展。
hash 函数有很多种用途,并且不同的函数可能需要不同的属性。有种称为 加密 hash 函数 的 hash 函数,出于安全目的必须满足一组限制性的属性 - 包括密码保护等应用程序,消息的完整性检查和指纹识别,以及数据损坏检测等等。但是这些超出本文的讨论范围。
非加密的 hash 函数也有很多用途,最常见的是 hash 表 ,这才是我们关注的,将在接下来详细探讨。
2. Hash 表介绍(Hash Maps)
想象一下我们需要保留一些俱乐部成员的所有成员名单,而且有搜索成员的需求。我们可以把他们保存在数组(或者链表)当中,执行搜索时,遍历列表的每一个元素直到我们找到他(比如说用他们的名字进行搜索)。在最坏的情况下,要遍历所有的成员(如果我们搜索的恰好是最后一个,或者根本不存在)。在复杂性理论术语中,搜索拥有 O(n) 的复杂度,列表比较小时相当快,但会随着成员的数量变多越来越慢。
怎么才能改进呢?我们假设所有的俱乐部成员都有一个成员 ~ID~,它正好是反映他们加入俱乐部的先后顺序。
按照 ID 搜索是可以接受的,我们把他们放到一个数组中,索引匹配他们的 IDs(比如: ID=10 就是数组的索引为 10 的元素)。这样搜索起来就非常方便了,事实上这是最高效的,复杂性为 O(1) ,也就是我们熟知的 常量时间 。
但是,俱乐部成员 ID 有可能是人为设置的,如果 IDs 很大的话,非连续的或者是随机数?又或者,如果通过 ID 搜索是不可接受的,需要按照名字(或者其它)字段进行搜索?同时能够处理任意数据集合和限制较少的搜索条件并且保持快速搜索肯定是很有用的。
这就是 hash 函数要解决的问题,合适的 hash 函数可以将任意的数据映射成整数,将会扮演之前类似成员 ID 的角色(虽然有些重要的区别)。
首先,好的 hash 函数通常输出范围比较宽(通常是 32-bit 或者 64-bit 的整个范围)。所以为所以可能的索引构建数组是不切实际的,也是巨大的资源浪费。为了解决这个问题,我们需要一个大小合理的数组(比如说,大小仅仅是要存储元素数量的两倍)并对 hash 结果进行 取模 运算得到数组的索引。所以,索引可能是 index = hash(object) mod N, N 是数组的大小。
其次,对象的 hashes 可能不是唯一的(除非对固定数据集合定制的完美 hash 函数,这不是我们的讨论范围)。会有 碰撞 (通过取模运算增加了),因此,简单的直接通过索引访问没啥用。 有几个方法可以解决这个问题,常用的办法是附加一个列表,通常称为 桶 ,每个数组存储了所有有相同索引的对象集合。
所以,我们有一个大小为 N 的数组,每个元素都指向一个对象桶。添加一个新的对象,需要计算 hash module N ,然后添加结果索引桶中元素是否存在,不存在时则添加。搜索对象,也是做相同的事情。这样的数据结构称之为 hash 表 ,虽然桶中的搜索是线性的,合理的 hash 表每个桶中应该有相当少的对象,几乎是常量时间内访问的(平均复杂度为 O(N/k), k 是桶的数量)。
对于复杂的对象,hash 函数通常不适用于整个对象,用 key 来代替。在俱乐部会员的例子中,每个对象可能包含多个字段(名字、年龄、地址、邮箱、联系方式等),但是我们选择其中的一个,比如说邮箱扮演 hash 函数中 key 的角色。事实上,key 也不一定需要是对象的一部分;使用键值对来存储对象是很常见的,key 通常是一个相对比较短的字符串,值可以是任意数据。这种情况下,hash 表或者 hash 映射通常用作 字典 ,也是一些高级语言实现对象或者关联数组的方式。
3. 横向扩展:分布式 hashing
现在我们继续讨论 hashing,是时候探讨 分布式 hashing 了。
很多情况下,可能有必要或者希望把 hash 表拆成几个部分,分别放在不同的服务器上。主要动机是绕过单台计算的内存限制,允许构造任意大的 hash 表(如果服务器是足够的话)。
在这种情况下,对象 分布 在多个服务中,名字也是这么由来的。
一个典型的例子是内存缓存的实现,比如 Memcached。
这类设置是由一组缓存服务器组成,存放很多个键值对,用做高速缓存。比如,减少数据库服务负载,提高性能,应用程序首先从缓存服务器拉取数据,如果存在的话就直接使用,不存在(缓存未命中)再从数据库中查询计算然后把结果选取合适的 key 缓存到缓存服务器中,这样下一次就可以直接使用了。
那么,分布式是如何进行的?使用什么方法来确定数据缓存在哪个服务器上?
最简单的方式是按照服务器数量 取模 ,也就是: server = hash(key) mode N ,N 是池子的大小。存值或者取值,客户端首先计算 hash 值,然后 module N 运算,通过产生的索引值找到相应的服务器(索引和 IP 建立映射关系)。注意,用来生成分布式 key 的 hash 函数必须在所有的客户端相同,但是不需要和缓存服务器中使用的相同(他们有自己的策略,相当于是做了两次 hash)。
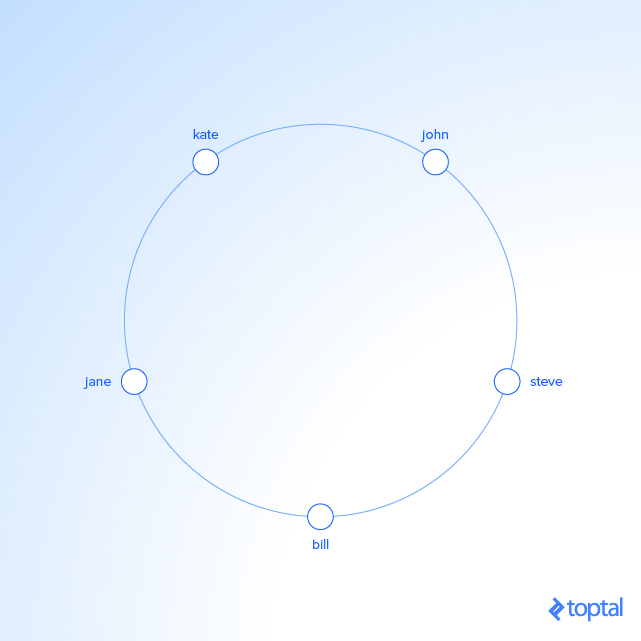
我们来看个例子,假设我们有 3 个服务器,A,B 和 C,我们有些带有 hash 值的字符串:
KEY HASH HASH mod 3 "john" 1633428562 2 "bill" 7594634739 0 "jane" 5000799124 1 "steve" 9787173343 0 "kate" 3421657995 2
客户端想要读取 key 为 john 的值,对它进行对 3 取模结果为 2 ,所以它应该去找 C 服务器,如果 key 不存在,客户端从源数据获取然后添加它到缓存。缓存池看起来像这样:
A B C
"john"
接下来另外一个客户端(或者同一个客户端)想要读取 key 为 bill 的值,它对 3 取模,结果为 0 ,所以它应该找 A 服务器,key 不存在,从换数据获取然后添加到缓存。之后缓存池应该像这样:
A B C "bill" "john"
把剩余的 key 都添加进来之后,缓存池是这样的:
A B C "bill" "jane" "john" "steve" "kate"
4. 重新出现的问题
这种分布式方案很简单、直接、可以正常通过。但问题是,如果服务器的数量发生变化(一台服务器崩溃了不可用、添加新的服务器、服务器下架等), 怎么办?需要重新把所有的 key 重新进行分配,大部分缓存失效了(因为取模的基数发生了变化,N 值变了,映射结果大部分就变了), 即便是添加或者删除一台服务器,所有服务器的 key 都可能要重新分配到不同的服务器中。
对于之前的例子,如果我们删掉 C 服务器,我们需要重新对所有的 keys hash 值对 2 进行取模运算,新的位置变成了:
KEY HASH HASH mod 2 "john" 1633428562 0 "bill" 7594634739 1 "jane" 5000799124 0 "steve" 9787173343 1 "kate" 3421657995 1
缓存服务器内容为:
A B "john" "bill" "jane" "steve" "kate"
注意所有的 key 的位置都变了,不只是原来在 C 上的 keys。
所有的 key 位置发生了变化,导致缓存失效,所有的数据都需要重新从原始的数据中获取然后再次缓存,这会极大的增加原始服务器(通常是 DB)的负载,甚至导致服务崩溃。
5. 解决方案:一致性 hash
那么,怎么解决这个问题?我们需要一个不直接依赖服务器数量的分布式的方案,以确保,添加或者删除服务器时,只有小部分 key 需要重新缓存。一个聪明且简单的人想了一个方案叫 一致性 hash ,第一次在 1997 年的 academic 论文被 Karger et al. at MIT 进行描述。
一致性 hashing 是一个分布式的 hashing 方案:通过在一个抽象圆上分配位置,它与分布式 hash 表中的服务器和对象的数量都无关, 称之为 hash 环 。这允许服务器和对象的扩展不会影响系统。
想象我们把 hash 的输出范围映射到圆的边上。也就是说最小的值 0 对应的是圆的 0°,而最大的值(最大整型称之为 INT_MAX )对应的 360° 。
并且所有的 hash 值将现行的分布在两者之间。所以,随便的 key,计算 hash 值,然后找到在圆边上的位置。
假设 INT_MAX 是 10^10,之前看到的值应该是这样:
KEY HASH ANGLE (DEG) "john" 1633428562 58.8 "bill" 7594634739 273.4 "jane" 5000799124 180 "steve" 9787173343 352.3 "kate" 3421657995 123.2
现在想想我们将服务器放在圆的边上,通过伪随机分配他们的角度。这个应该是以可重复的方式完成的(或者至少以所有的客户端同意的服务器角度的方式)。最简单的办法是对服务器名称(或者 IP 地址,某种 ID)进行 hash 处理。
在我们的例子中,事情看起来像这样:
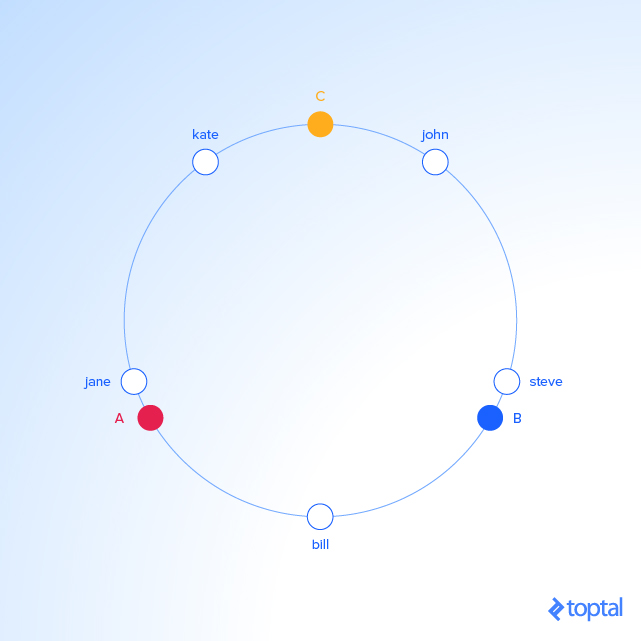
KEY HASH ANGLE (DEG) "john" 1633428562 58.8 "bill" 7594634739 273.4 "jane" 5000799124 180 "steve" 9787173343 352.3 "kate" 3421657995 123.2 "A" 5572014558 200.6 "B" 8077113362 290.8 "C" 2269549488 81.7
由于我们在同一个圆上既有对象又有服务器的 key,我们可以定义一个简单的规则把前者和后者联系起来:每个对象的 key 都属于跟它最近的服务器,逆时针方向(或者顺时针也行,看你的习惯)。换句话说,根据给定的 key 可以找到对应的服务器,我们需要在圆上沿着上升角的方向移动,直到找到服务器为止。
在我们的例子中:
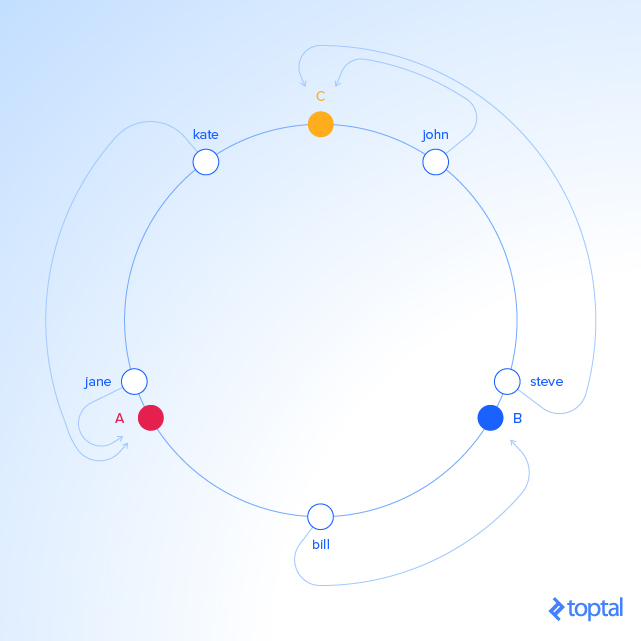
KEY HASH ANGLE (DEG) "john" 1633428562 58.7 "C" 2269549488 81.7 "kate" 3421657995 123.1 "jane" 5000799124 180 "A" 5572014557 200.5 "bill" 7594634739 273.4 "B" 8077113361 290.7 "steve" 787173343 352.3
以对象 key 为维度:
KEY HASH ANGLE (DEG) LABEL SERVER "john" 1632929716 58.7 "C" C "kate" 3421831276 123.1 "A" A "jane" 5000648311 180 "A" A "bill" 7594873884 273.4 "B" B "steve" 9786437450 352.3 "C" C
从编程角度看,我们要做的是保持服务器值的保持有序(它可以是任何实际区间的中的角度或者数字),遍历这个列表(或者使用二分查找),找到第一个比所需 key 大于等于的值。如果找不到这样的值,就取列表中的第一个值。
为了确保对象的 key 能够在服务器之间均匀的分布,我们需要一个简单的技巧:为每个服务器分配不止一个 label,而不是按照把我们的服务器 A~,~B~,~C 一对一的作为 label。比如说我们将拆分成: A0 .. A8, B0 .. B9, C0 .. C9 ,所有的都穿插在圆里,增加 label 的数量(服务器 keys)的因素,称之为 _权重_,具体如何分配要识情况而定,甚至可以通过调整 labels 的数量来调整在每个服务器的 keys 的分布概率。比如,~B~ 是其它服务器性能的两倍,它就可以配置被分配两倍的标签,最终它会持有两倍的对象(如果 keys 分布足够平均的话)。
对于我们的例子,我们假设所有三台服务器的权重等于 10(对于三台服务器是这样,10 到 50 台服务器,100 到 500 范围内的权重可以更好的工作,更大的池也能需要更高的权重):
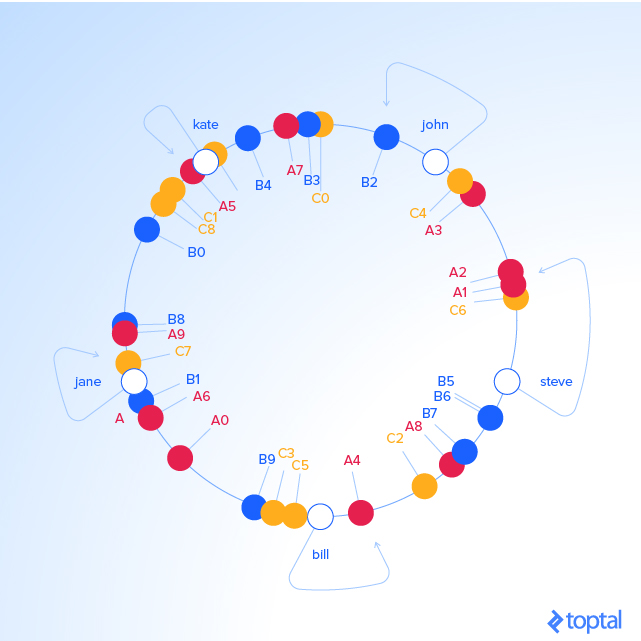
KEY HASH ANGLE (DEG) "C6" 408965526 14.7 "A1" 473914830 17 "A2" 548798874 19.7 "A3" 1466730567 52.8 "C4" 1493080938 53.7 "john" 1633428562 58.7 "B2" 1808009038 65 "C0" 1982701318 71.3 "B3" 2058758486 74.1 "A7" 2162578920 77.8 "B4" 2660265921 95.7 "C9" 3359725419 120.9 "kate" 3421657995 123.1 "A5" 3434972143 123.6 "C1" 3672205973 132.1 "C8" 3750588567 135 "B0" 4049028775 145.7 "B8" 4755525684 171.1 "A9" 4769549830 171.7 "jane" 5000799124 180 "C7" 5014097839 180.5 "B1" 5444659173 196 "A6" 6210502707 223.5 "A0" 6511384141 234.4 "B9" 7292819872 262.5 "C3" 7330467663 263.8 "C5" 7502566333 270 "bill" 7594634739 273.4 "A4" 8047401090 289.7 "C2" 8605012288 309.7 "A8" 8997397092 323.9 "B7" 9038880553 325.3 "B5" 9368225254 337.2 "B6" 9379713761 337.6 "steve" 9787173343 352.3
对象 keys 和 label 以及服务器的对应关系:
KEY HASH ANGLE (DEG) LABEL SERVER "john" 1632929716 58.7 "B2" B "kate" 3421831276 123.1 "A5" A "jane" 5000648311 180 "C7" C "bill" 7594873884 273.4 "A4" A "steve" 9786437450 352.3 "C6" C
这种环形策略的好处是什么呢?如果 C 服务器被移除掉了。当被移除时,我们需要在圆上删掉 C0 .. C9 的 label,
这导致了以前在 Cx 上的 keys 随机标记为 Ax 和 Bx ,将他们重新分配给 A 和 B 。
但是其他的对象 key 会发生什么呢?什么都不会变!这就是它牛逼的地方,
Cx 标签不会已任何方式影响这些 keys。所以删除一个服务器只会影响这台服务器的对象 keys,剩下的 keys 不会有任何影响。
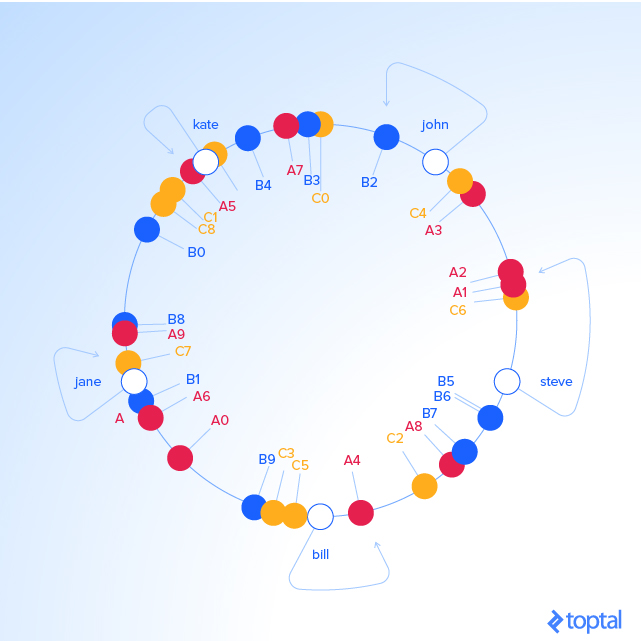
KEY HASH ANGLE (DEG) "A1" 473914830 17 "A2" 548798874 19.7 "A3" 1466730567 52.8 "john" 1633428562 58.7 "B2" 1808009038 65 "B3" 2058758486 74.1 "A7" 2162578920 77.8 "B4" 2660265921 95.7 "kate" 3421657995 123.1 "A5" 3434972143 123.6 "B0" 4049028775 145.7 "B8" 4755525684 171.1 "A9" 4769549830 171.7 "jane" 5000799124 180 "B1" 5444659173 196 "A6" 6210502707 223.5 "A0" 6511384141 234.4 "B9" 7292819872 262.5 "bill" 7594634739 273.4 "A4" 8047401090 289.7 "A8" 8997397092 323.9 "B7" 9038880553 325.3 "B5" 9368225254 337.2 "B6" 9379713761 337.6 "steve" 9787173343 352.3
对象 key 和 label 以及 服务器 的映射关系:
KEY HASH ANGLE (DEG) LABEL SERVER "john" 1632929716 58.7 "B2" B "kate" 3421831276 123.1 "A5" A "jane" 5000648311 180 "B1" B "bill" 7594873884 273.4 "A4" A "steve" 9786437450 352.3 "A1" A
如果发生类似的事情,不是删掉一台服务器,而是添加一个新的。如果我们添加一个新的服务器 D 到我们例子中
(比如说,作为 C 的替代品),我们会增加 labels D0 .. D9 。结果是将现在的 1/3 的已经存在的 keys 重新赋值给 D ,
而且其余的部分保持不变:
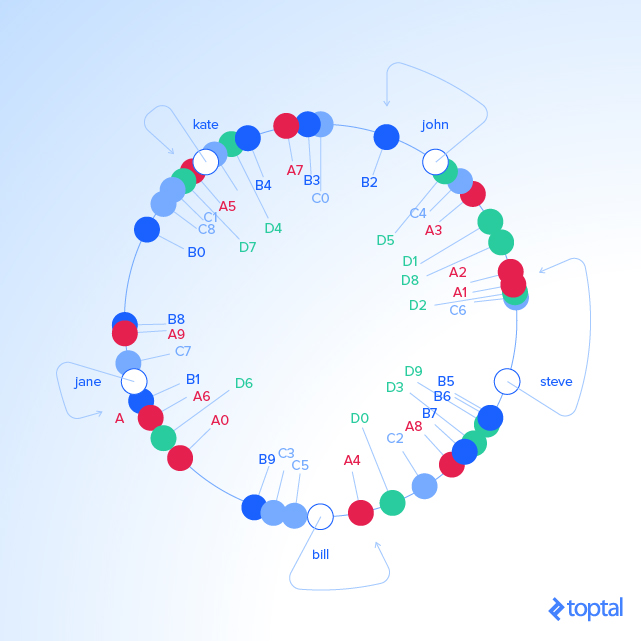
KEY HASH ANGLE (DEG) "D2" 439890723 15.8 "A1" 473914830 17 "A2" 548798874 19.7 "D8" 796709216 28.6 "D1" 1008580939 36.3 "A3" 1466730567 52.8 "D5" 1587548309 57.1 "john" 1633428562 58.7 "B2" 1808009038 65 "B3" 2058758486 74.1 "A7" 2162578920 77.8 "B4" 2660265921 95.7 "D4" 2909395217 104.7 "kate" 3421657995 123.1 "A5" 3434972143 123.6 "D7" 3567129743 128.4 "B0" 4049028775 145.7 "B8" 4755525684 171.1 "A9" 4769549830 171.7 "jane" 5000799124 180 "B1" 5444659173 196 "D6" 5703092354 205.3 "A6" 6210502707 223.5 "A0" 6511384141 234.4 "B9" 7292819872 262.5 "bill" 7594634739 273.4 "A4" 8047401090 289.7 "D0" 8272587142 297.8 "A8" 8997397092 323.9 "B7" 9038880553 325.3 "D3" 9048608874 325.7 "D9" 9314459653 335.3 "B5" 9368225254 337.2 "B6" 9379713761 337.6 "steve" 9787173343 352.3
对象 key 和 label 以及 服务器 的对应关系:
KEY HASH ANGLE (DEG) LABEL SERVER "john" 1632929716 58.7 "B2" B "kate" 3421831276 123.1 "A5" A "jane" 5000648311 180 "B1" B "bill" 7594873884 273.4 "A4" A "steve" 9786437450 352.3 "D2" D
这就是如何解决重新 hash 一致性问题的办法。通常,只有当 k/N 的 key 需要重新建立映射, k 是 keys 的总量,而 N 是服务器的数量。
6. 接下来干些什么?
我们观察到使用分布式缓存在优化性能时,缓存服务器的数量可能发生变化(可能是服务器崩溃、添加或者删除服务器以扩大和减少总体容量)。通过使用 hash 一致性在服务器之前分配 keys,如果发生了这种情况,我们可以知晓重新分配的 keys 的数量,将原始数据服务器的影响降到最低,防止出现潜在的性能问题甚至是宕机的情况。
有几个系统的客户端,比如说 Memcached 和 Redis,都提供了开箱即用的 hash 一致性的支持。
或者,你可以自己用你喜爱的编程语言实现算法,一旦你理解了这个概念,实现应该是相对容易的。