DevOps - 日志收集 ELK
Table of Contents
1. 一个简易的日志收集方案
设计图:
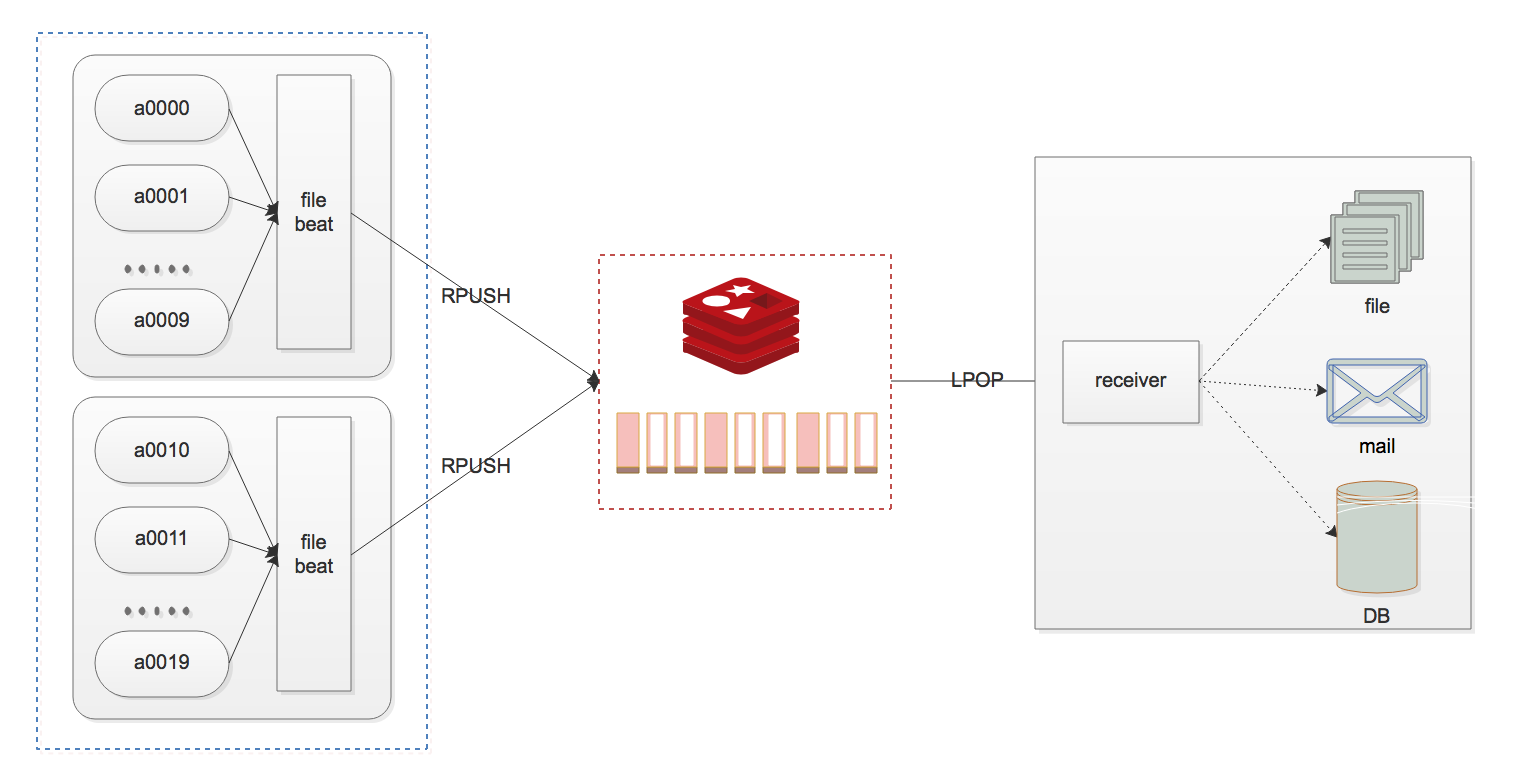
- 主机使用 filebeat 上报日志到 Redis (
list等) - 起一个服务「订阅」Redis
list中的日志,然后:- 按照文件名称保存到本地
- 根据日志中的日志级别进行告警通知
- 按需求将只是保存到 MySQL 或者 MongoDB 中(分表分库)
可优化的地方:
- 此方案适合业务量不是很大的情况下,
1000条/秒应该是抗的住的(360万/小时),如果业务量比这个更大怎么办:- redis 拆分成多通道,水平拆分,或者换成 Kafka
- 业务日志可以已 JSON 的方式打出,更方便检索
2. ELK
上面只是一个简易的日志收集方案,业内常用的标准是 ELK:
- E lasticsearch 分布式的搜索和分析引擎
- L ogstash 是一个流式数据收集引擎
- K ibana 数据可视化
Elastic 技术栈和产品文档:https://www.elastic.co/guide/index.html
ELK 是一个技术栈,随着技术的发展,加上实际的业务场景会有一些取舍。也不全是用 ELK 这一套,也不仅限于这三个。
针对收集又衍生了 Beats,是跑在服务器上的代理,用来收集数据然后发送到 ES。有很多的 Beats,比如最常用的: 日志文件收集 filebeat,就是专门用来做日志收集;还有 Metricbeat 收集 metric 等。
然后,日志数据量很大时,往往会引入 Kafka 做数据缓冲或者架构解耦(日志被多个订阅),Kafka 越来越成为主流的情况下, ELK 技术栈现在也有很多人称为 EFK。
但是实际的架构非常灵活,正如上面所说要看场景,还有流量有多大。可以:
| 收集 | 中间层 | 存储、搜索、分析 | 展示 | |
|---|---|---|---|---|
| #1 | logstash | ES | Kibana | |
| #2 | filebeat | ES | Kibana | |
| #3 | filebeat | logstash | ES | Kibana |
| #4 | filebeat | Kafka -> logstash | ES | Kibana |
灵活的架构还包括:
- 收集层有些公司业务比较复杂的情况下,希望在收集日志时加一些额外的信息(比如应用信息等),比较简单的 filebeat/logstash 也可以实现,但是复杂的逻辑往往也需要添加收集规则,或者二次开发,又或者自研
- 流量比较大的时候,一般都会引入 Kafka,而 logstash 的性能常被人诟病,所以通常被自研的服务代替 自研的成本并不高,逻辑就是从 Kafka 订阅数据,然后进行一些 清洗 输出到 ES
- 对于日志分析和展示也可以自研,不用 Kibana 也行,而且 Kibana 有些学习的成本,有些业务场景比较简单没必要用 Kibana
说明:
- ELK 中最核心的组件其实是 ES,不然如何架构 ES 几乎都是绕不开的,自研的成本有点高了…
- Kakfa 的解耦往往用在从主机上收集的日志,不仅仅给日志平台用,业务方也无需要使用,这种情况下要么自己订阅消息, 要么用调用 ES API 来实现
3. 组件
beats 的 目录结构,以及默认的配置。
https://www.elastic.co/guide/en/beats/journalbeat/current/directory-layout.html
3.1. Journalbeat
https://www.elastic.co/guide/en/beats/journalbeat/master/index.html
安装:
curl -L -O https://artifacts.elastic.co/downloads/beats/journalbeat/journalbeat-7.8.0-x86_64.rpm sudo rpm -vi journalbeat-7.8.0-x86_64.rpm
配置:
配置文件路径: /etc/journalbeat/ ,一些重要的选项:
journalbeat.inputs 控制日志输入。
seek 选项控制 Journalbeat 开始读取日志的位置,有三个可选值,默认是 cursor:
head每次都从头开始读,重启之后还是从头开始读;tail跟 tail 指令一样,每次都从最后开始读,重启之后也是从最后开始读,可能会导致日志重复。cursor首次读取从文件开头开始读取,但是重启之后还是从最后一次读取的位置继续开始。
include_matches 选项用于过滤收集的日志(否则所有的 journalctl 的日志都会被收集)。格式是 field=value 的列表。不支持正则表达式。
引用字段,支持两种方式:
- systemd journal 使用的字段名,比如:
CONTAINER_TAG=redis - Journalbeat 翻译后的字段,比如:
container.image.tag=redis
字段的对应关系(支持的过滤关键字):https://www.elastic.co/guide/en/beats/journalbeat/current/configuration-journalbeat-options.html#translated-fields
比较常用的几个字段:
_SYSTEMD_UNITsystemd unit
输出:journalbeat 支持多种输出, Elasticsearch, LogStash, Kafka, Redis, File, Console, Elastic Cloud 等。
https://www.elastic.co/guide/en/beats/journalbeat/current/configuring-output.html