Kubernetes 架构
Table of Contents
Kubernetes 遵循客户端服务器的架构。由几个(为了高可用)master 节点来管理集群,实际运行服务的是工作节点(Worker node)。 Master 节点主要包含 kube-apiserver、etcd 存储、kube-controller-manager 、kube-scheduler 和 services 的 DNS 服务; 工作节点包含容器运行时(Docker)、kubelet 和 kubeproxy。
架构图:
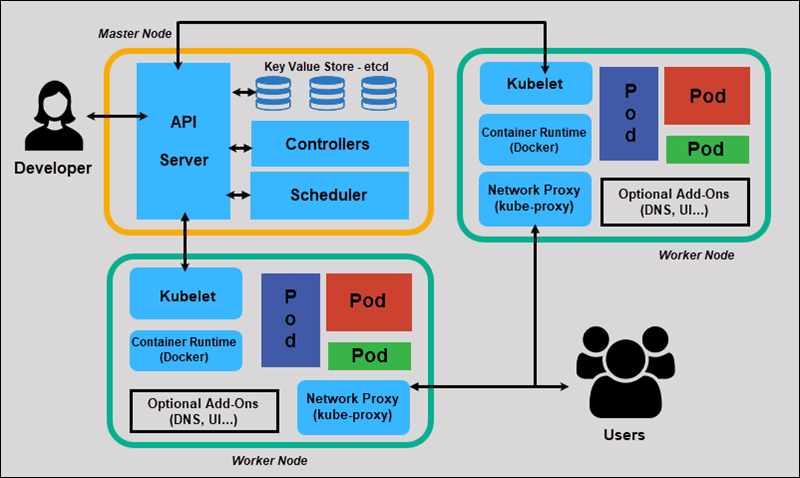
Master node 通常被视为控制平面(Control plane),而 Workder Node 被视为计算机器。
1. Master Node
1.1. etcd 存储
etcd 是用于分布式系统中最关键数据的的分布式的可靠的 key-value 存储。Kubernetes 用它来存储集群中的数据(比如 pods 的数量和状态,namespace 等)、 API 对象和服务发现信息的详细信息等。
出于安全的原因,它只允许被 API server 访问。etcd 在 watcher 的帮助下,向集群发出有关配置修改的通知。
它是分布式的系统,可以单独部署,也通常与 master 一起部署,遵从 3、5、7 等奇数个部署。
1.2. API server
API server 充当的是集群的前端。顾名思义,所有与集群的交互都要通过 API server,它接受所有的 REST 请求,所有对 Pods, Services、RS/RC 或者其它 api 对象的变更都要通过它。
它也是与 etcd 通信的唯一组件,保证数据存储在 etcd 中,并且与部署的 pods 信息一致。
1.3. kube-controller-manager
controll manager 是一系列的控制器后台进程组成,但是为了部署和管理方便,打包到了一起。比如,副本控制器(replication controller)来控制容器中副本的数量; 端点控制器(endpoint controller)来控制端点对象类似 services 和 pods。
这些控制器的职责都是保证整个集群的期望状态与集群状态一致。当一个服务的配置变更时,控制器会让集群按照变更的期望状态来工作。
1.4. kube-scheduler
scheduler,调度器,根据调度策略将 pod 调度到符合条件的节点上。
调度会参考请求的资源、整个集群中每个节点的工作负载、软硬件的策略限制、亲和性和反亲和性、负载干扰等对每个节点进行评分,最终选择出一个评分最高的节点。
实际的工作流程大致为:
- scheduler 监听 API server,获取 PodSpec.NodeName 为空的 Pod
- 根据调度策略(过滤、打分)选出一个最优的节点
- 通知 API server 将 pod 绑定到该节点上
2. Worker Node
2.1. 容器运行时(container runtime)
容器运行是是容器的运行环境(用来支撑容器启停),遵从 CRI 规范的实现都可,一般使用 Docker(但你也可以用其它的)1。
CRI 由 protocol buffers、gRPC API 和库组成,kubelet 充当的是 gRPC client 的角色,与 CRI 的实现进行通信达到对容器的控制。
2.2. kubelet
节点上的主要服务(local agent),主要和 kube-apiserver 交互创建新的 pod 或者修改 pod 的规格,确保 pods 的健康在期望(desired) 状态下运行。
它还定时向 master 汇报节点的运行状态(pod 状态、节点是否健康和资源利用率等)。
通俗来将,可以说 kubelet 负责维护 apiserver 分配给该节点的一群 pod,使它们的状态与集群的期望保持一致。 事实上,它可以脱离 master 单独运行2。
2.3. kube-proxy
kube-proxy 是节点上运行的代理服务,它配合 services 将请求正确的转发到对应的 pods 或者容器中。
实际的实现是 kube-proxy 通过监听 apiserver 中 service 对象的变更,然后修改 iptables 规则达到服务转发的效果。